
Dexterous robotic hands manipulate thousands of objects with ease

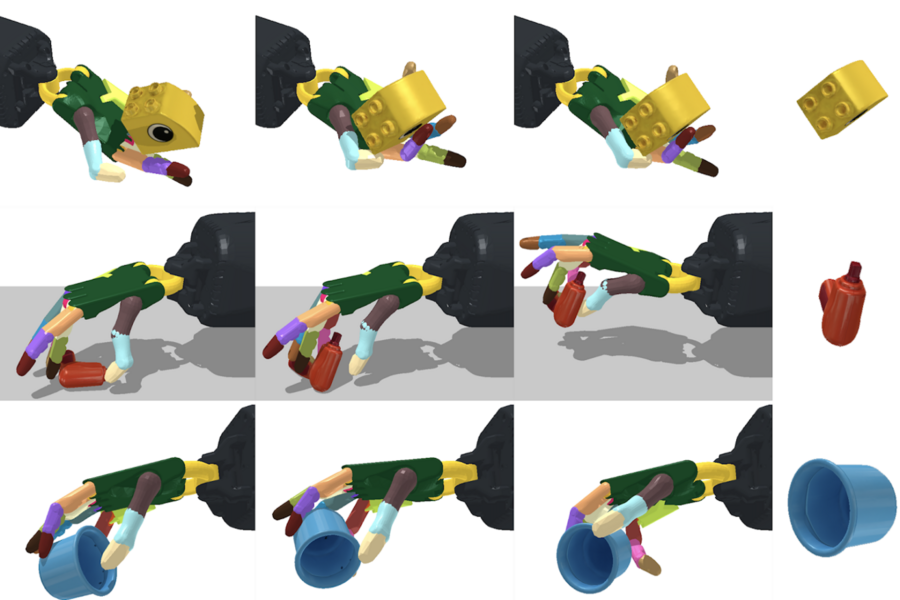 A new system can reorient over 2,000 different objects, with the robotic hand facing both upwards and downwards. Credits:Image courtesy of MIT CSAIL.
A new system can reorient over 2,000 different objects, with the robotic hand facing both upwards and downwards. Credits:Image courtesy of MIT CSAIL. At just one year old, a baby is more dexterous than a robot. Sure, machines can do more than just pick up and put down objects, but we’re not quite there as far as replicating a natural pull toward exploratory or sophisticated dexterous manipulation goes.
Artificial intelligence firm OpenAI gave it a try with Dactyl (meaning “finger,” from the Greek word “daktylos”), using their humanoid robot hand to solve a Rubik’s cube with software that’s a step toward more general AI, and a step away from the common single-task mentality. DeepMind created “RGB-Stacking,” a vision-based system that challenges a robot to learn how to grab items and stack them.
Scientists from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), in the ever-present quest to get machines to replicate human abilities, created a framework that’s more scaled up: a system that can reorient over 2,000 different objects, with the robotic hand facing both upwards and downwards. This ability to manipulate anything from a cup to a tuna can to a Cheez-It box could help the hand quickly pick-and-place objects in specific ways and locations — and even generalize to unseen objects.
This deft “handiwork” — which is usually limited to single tasks and upright positions — could be an asset in speeding up logistics and manufacturing, helping with common demands such as packing objects into slots for kitting, or dexterously manipulating a wider range of tools. The team used a simulated, anthropomorphic hand with 24 degrees of freedom, and showed evidence that the system could be transferred to a real robotic system in the future.
“In industry, a parallel-jaw gripper is most commonly used, partially due to its simplicity in control, but it’s physically unable to handle many tools we see in daily life,” says MIT CSAIL PhD student Tao Chen, member of the MIT Improbable AI Lab and the lead researcher on the project. “Even using a plier is difficult because it can’t dexterously move one handle back and forth. Our system will allow a multi-fingered hand to dexterously manipulate such tools, which opens up a new area for robotics applications.”
This type of “in-hand” object reorientation has been a challenging problem in robotics, due to the large number of motors to be controlled and the frequent change in contact state between the fingers and the objects. And with over 2,000 objects, the model had a lot to learn.
The problem becomes even more tricky when the hand is facing downwards. Not only does the robot need to manipulate the object, but also circumvent gravity so it doesn’t fall down.
The team found that a simple approach could solve complex problems. They used a model-free reinforcement learning algorithm (meaning the system has to figure out value functions from interactions with the environment) with deep learning, and something called a “teacher-student” training method.
For this to work, the “teacher” network is trained on information about the object and robot that’s easily available in simulation, but not in the real world, such as the location of fingertips or object velocity. To ensure that the robots can work outside of the simulation, the knowledge of the “teacher” is distilled into observations that can be acquired in the real world, such as depth images captured by cameras, object pose, and the robot’s joint positions. They also used a “gravity curriculum,” where the robot first learns the skill in a zero-gravity environment, and then slowly adapts the controller to the normal gravity condition, which, when taking things at this pace, really improved the overall performance.
While seemingly counterintuitive, a single controller (known as brain of the robot) could reorient a large number of objects it had never seen before, and with no knowledge of shape.
“We initially thought that visual perception algorithms for inferring shape while the robot manipulates the object was going to be the primary challenge,” says MIT Professor Pulkit Agrawal, an author on the paper about the research. “To the contrary, our results show that one can learn robust control strategies that are shape-agnostic. This suggests that visual perception may be far less important for manipulation than what we are used to thinking, and simpler perceptual processing strategies might suffice.”
Many small, circular shaped objects (apples, tennis balls, marbles), had close to 100 percent success rates when reoriented with the hand facing up and down, with the lowest success rates, unsurprisingly, for more complex objects, like a spoon, a screwdriver, or scissors, being closer to 30 percent.
Beyond bringing the system out into the wild, since success rates varied with object shape, in the future, the team notes that training the model based on object shapes could improve performance.
Chen wrote a paper about the research alongside MIT CSAIL PhD student Jie Xu and MIT Professor Pulkit Agrawal. The research is funded by Toyota Research Institute, Amazon Research Award, and DARPA Machine Common Sense Program. It will be presented at the 2021 The Conference on Robot Learning (CoRL).
Media Inquiries
Journalists seeking information about EECS, or interviews with EECS faculty members, should email eecs-communications@mit.edu.
Please note: The EECS Communications Office only handles media inquiries related to MIT’s Department of Electrical Engineering & Computer Science. Please visit other school, department, laboratory, or center websites to locate their dedicated media-relations teams.